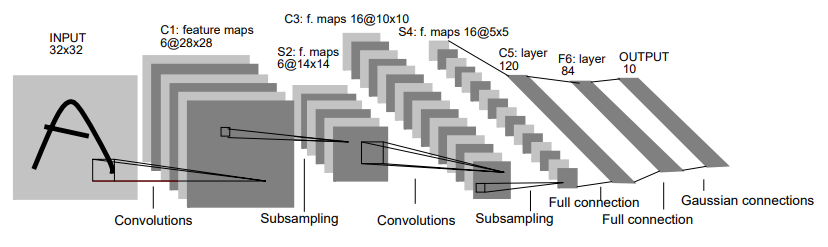
ディープラーニングの歴史を振り返るシリーズの第二弾です。
前回は元祖1989年に発表されたLeNetを勉強したので、今回は1998年に発表されたLeNet5(http://vision.stanford.edu/cs598_spring07/papers/Lecun98.pdf)を実装してみました。

LeNet5は発表当時のLeNetとは異なりPooling 層があるなど、現代のCNNとほぼ違いがないモデルとなっており元祖CNNと言われる理由が納得です。
LeNet5とは
LeNet5は3層の畳み込み層と2層の全結合層と2層のPooling層からできているモデルのことです。
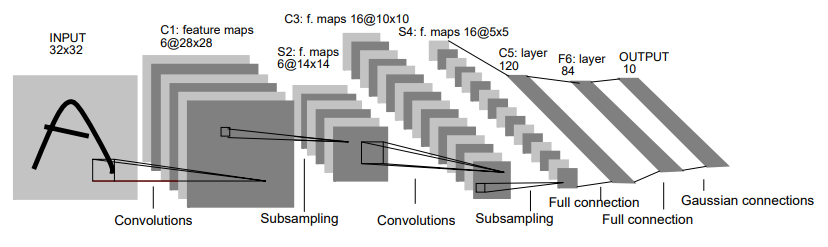
最近のCNNと比べるとPooling層にMaxPoolingではなく重み付きのAveragePoolingを使っているという特徴があります。
また、AlexNet以降ではPooling層を通したあとは活性化関数を通らないのですが、LeNetでは畳み込み層や全結合層だけではなく、Pooling層の後にも活性化関数を通っているという特徴があります。
活性化関数はtanhが使われており、ここは前回紹介した初代LeNetと同じになっています。
また上の図のC3の特徴マップの取り方が最近のCNNとは大きく異なっています。
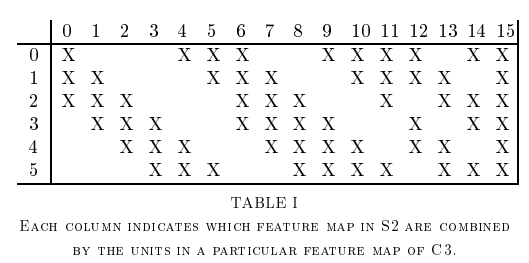
論文のTABLE1を見ると0チャンネル目は前層の0, 1, 2チャンネル目だけを使う。
1チャンネル目は前層の1, 2, 3チャンネル目を使っているという風にチャンネル毎に一部のチャンネルをmaskしているようです。
これはチャンネルごとに異なるチャンネルをとることで異なる特徴を取り出そうとしているようです。
LeNet5の実装
それではLeNet5を実装してみます。
今回は論文通りではなく少し現代的な実装をしてみます(PyTorchでチャンネルごとにmaskしたりするのが面倒だっただけですが…)。
# -*- coding: utf-8 -*-
import torch
from torch import nn
class LeNet5(nn.Module):
def __init__(self) -> None:
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(
in_channels=1, out_channels=6, kernel_size=5,
stride=1, padding=0)
self.avgpool1 = nn.AvgPool2d(2, 2)
self.conv2 = nn.Conv2d(
in_channels=6, out_channels=16, kernel_size=5,
stride=1, padding=0
)
self.avgpool2 = nn.AvgPool2d(2, 2)
self.conv3 = nn.Conv2d(
in_channels=16, out_channels=120, kernel_size=5,
stride=1, padding=0
)
self.fc1 = nn.Linear(120, 84)
self.fc2 = nn.Linear(84, 10)
def forward(self, x):
x = torch.tanh(self.conv1(x))
x = torch.tanh(self.avgpool1(x))
x = torch.tanh(self.conv2(x))
x = torch.tanh(self.avgpool2(x))
x = torch.tanh(self.conv3(x))
x = torch.tanh(self.fc1(x.view(-1, 120*1*1)))
x = self.fc2(x)
return xMNISTを学習させてみた
前回同様、MNISTを100epoch学習させてみました。
import torch
import torchvision
import torchvision.transforms as transforms
from torch import nn, optim
from LeNet5 import LeNet5
preprocess = transforms.Compose([
transforms.Resize(32),
transforms.ToTensor(),
])
trainset = torchvision.datasets.MNIST(
root='../data',
train=True,
download=True,
transform=preprocess
)
testset = torchvision.datasets.MNIST(
root='../data',
train=False,
download=True,
transform=preprocess
)
batch_size = 100
trainloader = torch.utils.data.DataLoader(
trainset,
batch_size=batch_size,
shuffle=True,
)
testloader = torch.utils.data.DataLoader(
testset,
batch_size=batch_size,
shuffle=False,
)
# 使用するデバイスの設定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# 損失関数とオプティマイザの定義
net = LeNet5()
net = net.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01)
# ネットワークの訓練
epochs = 100
net.train()
for epoch in range(epochs):
loss = None
count = 0
train_acc = 0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 訓練データの精度を計算
pred = outputs.argmax(dim=1, keepdim=True)
train_acc += pred.eq(labels.view_as(pred)).sum().item()
count += inputs.shape[0]
train_acc = (train_acc/count) * 100
print("epoch{:d}/{:d} train_loss:{:.3f} train_acc:{:.2f}".format(epoch+1, epochs, loss, train_acc))
# モデルを保存
torch.save(net.state_dict(), './LeNet_mnist.pth')
# testデータで評価
test_acc = 0
count = 0
net.eval()
with torch.no_grad():
for data in testloader:
inputs, labels = data[0].to(device), data[1].to(device)
outputs = net(inputs)
pred = outputs.argmax(dim=1, keepdim=True)
test_acc += pred.eq(labels.view_as(pred)).sum().item()
count += inputs.shape[0]
acc = (test_acc / count) * 100
print(acc)テストデータに対する精度は98.79%とかなり良い結果です。
初代LeNetと比べるとPooling層で重要な特徴を圧縮しているのが有効なことが分かります。
参考
LeCun, Yann, et al. “Gradient-based learning applied to document recognition.” Proceedings of the IEEE 86.11 (1998): 2278-2324.

コメント